DDIA系列 - 分布式部分 - 1
Publish date: Oct 319, 31039
Last updated: Oct 289, 28089
Last updated: Oct 289, 28089
为何使用分布式
主要是出于如下考虑:
可扩展性
数据量、读负载 或 写负载 大到单机无法处理,分摊负载
容错与高可用性
提供 HA 保证,允许单点故障
延迟
将服务部署到离客户最近的机器上,降低延迟
系统扩展能力
纵向扩展/垂直扩展
共享内存架构
堆配置,加 CPU、加内存、加磁盘,提高计算和存储能力
优点:简单,能提供有限的容错能力,因为高端服务器的组件都是热插拔的
缺点:
- 无法提供异地容错能力
- 成本增长非线性,两倍配置不能带来两倍的性能提升
共享磁盘架构
计算节点与存储节点分离:
- 计算节点具备强大的 CPU 和 内存
- 存储节点具备强大的 I/O 能力,比如用磁盘阵列或SSD等
- 计算节点与存储节点之间用高速网络,比如 IB 网络或 NAS
- 适用于 数据仓库 等负载
缺点:
- 资源竞争以及锁的开销等限制了其进一步的扩展能力
横向扩展/水平扩展
无共享架构,完全分布式
这种架构下,每台机器都称为一个节点,具有独立的 CPU、内存和磁盘
节点之间的通信使用传统的以太网上,使用软件来协调运作
优点:
- 不需要专门的硬件,具有较高的性价比
- 跨多个地理区域,可以就近减少访问延迟
- 能在数据中心挂了的情况下继续工作,较高的容错能力
缺点:给应用带来了更高的复杂性
复制与分区
数据分布在多个节点上有两种常见的方式:复制 与 分区
复制
英文:Replication
多个节点上保存相同数据的副本,提供冗余,并且提高系统性能
分区
英文:Partition,有时也称为分片,即 Sharding
将大块头的数据库拆分成更小的子集,不同的子集分配给不同的节点存储
总结
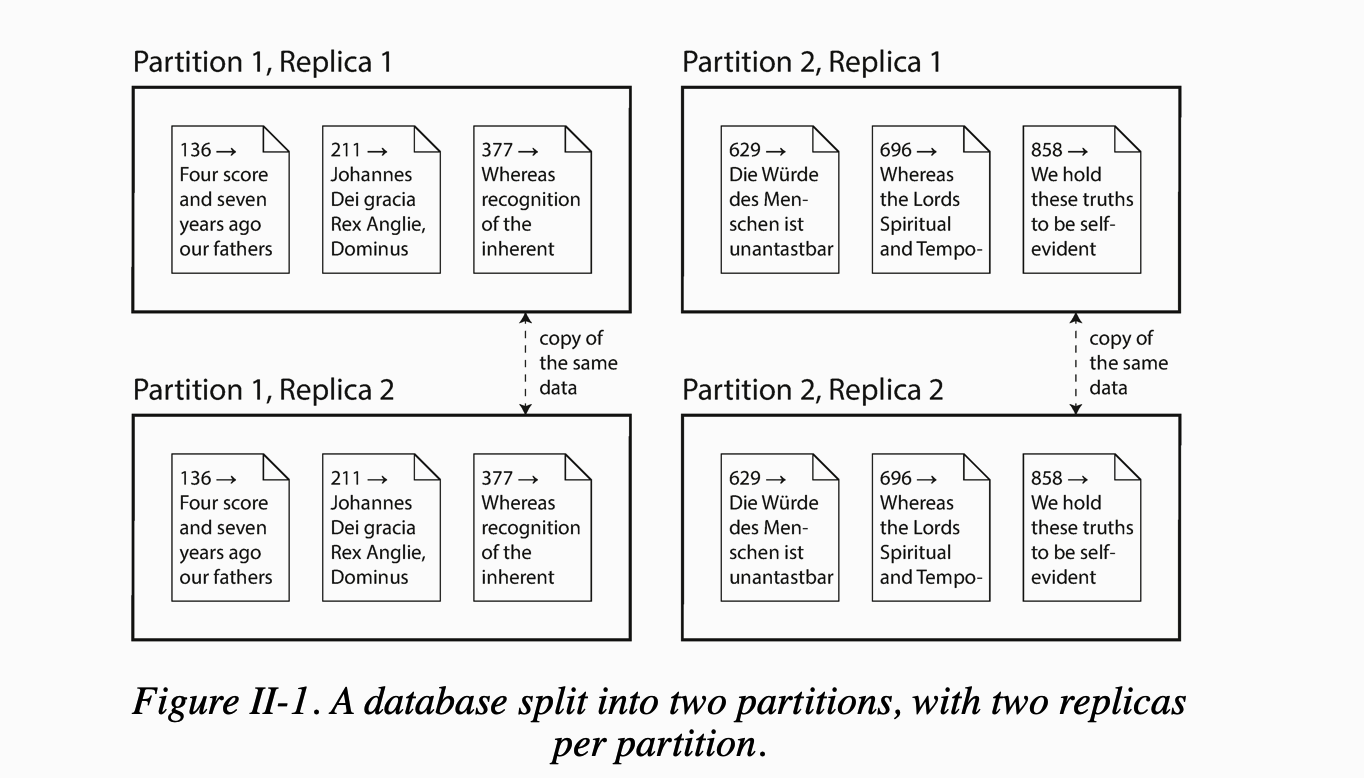
复制 与 分区 是配合使用的,如下图:
参考文献
What Every Programmer Should Know About Memory
Shared Nothing vs. Shared Disk Architectures: An Indenpendent View